AI Guide
3 min read
250 views
Shocking: Google's nano-banana Model Explains DPO
Discover how Google's nano-banana model explains Direct Preference Optimization (DPO) in simple terms. This article breaks down the DPO loss function, its components, and why it offers a more stable alternative to traditional reinforcement learning methods for aligning AI with human preferences.
This article is part of the ImageFlow AI Blog, our content hub within the broader ImageFlow AI. Discover how Nano Banana works to explore the tools in depth.
We regularly share nano banana tips, nano banana prompt ideas, and nano banana vs other AI tools to keep your creativity flowing.
I
ImageFlow AI Team
AI enthusiasts dedicated to making artificial intelligence accessible to everyone.
November 24, 2025
@nanobananaguide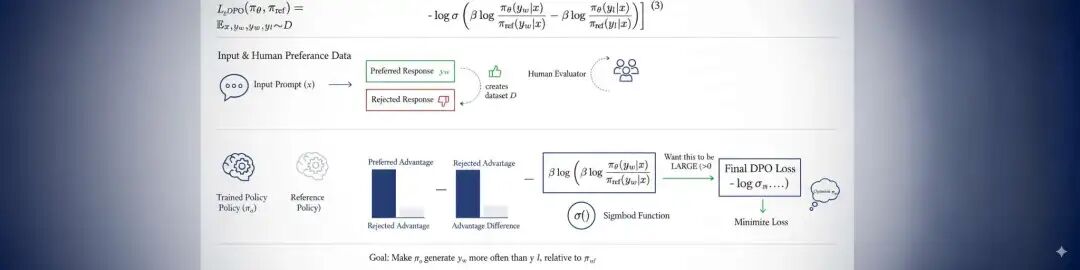
DPO
Direct Preference Optimization
AI alignment
machine learning


